


Extraktion:
Zunächst wurden Daten über verschiedene Schnittstellen (APIs), insbesondere die Google Pagespeed API, gewonnen. Darüber hinaus wurde eine spezielle Crawling-Software für die Analyse von Website-Problemen und Optimierungsmöglichkeiten verwendet. Die Befehle und API-Abfragen werden mithilfe von Python-Skripten durchgeführt. So werden Rohdaten, meist im JSON- oder CSV-Format, gewonnen. Abbildung 1 zeigt die typische Struktur von Rohdaten aus einer API-Abfrage.
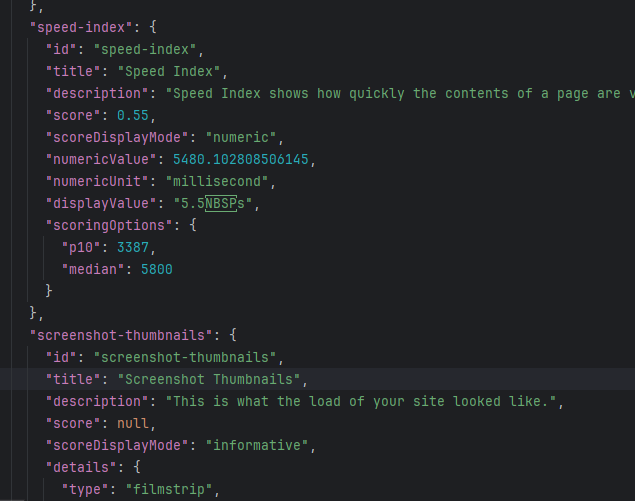
Abbidung 1: Rohdaten im JSON-Format
Im Anschluss an die Extraktion werden die Rohdaten mithilfe von Funktionen von Python-Bibliotheken zur Datenanalyse und -verarbeitung wie Pandas und NumPy analysiert, bereinigt und transformiert. Dies ermöglicht die Extraktion relevanter KPIs aus den gesammelten Daten und die Überführung der Daten in ein strukturiertes Format. So werden die Daten für den nächsten Prozessschritt, nämlich das Laden an den gewünschten Zielort, vorbereitet. In Abbildung 2 ist das Ergebnis der Transformation von Rohdaten in ein strukturiertes Format dargestellt.
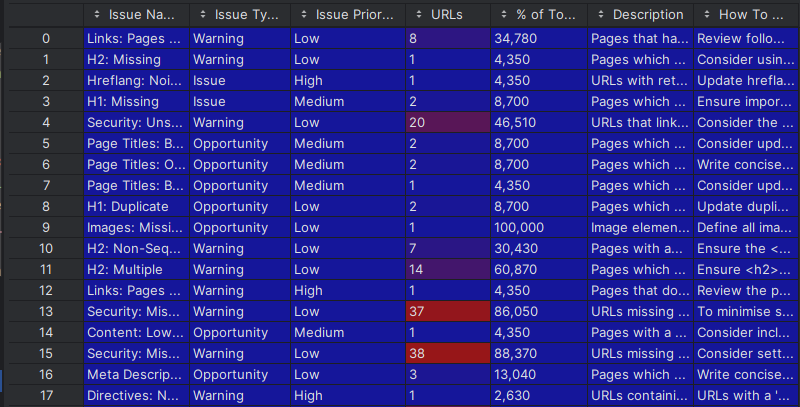
Abbidung 2: Sturkturierte Daten als Ergebnis des Transformationsprozesses
Ein zusätzlicher Aspekt, der bei der Implementierung der ETL-Pipeline berücksichtigt wurde, ist die automatisierte Aktualisierung der Daten. Durch eine planmäßige Ausführung der Skripte wird eine fortlaufende Datenerfassung sichergestellt. Die cloudbasierte Datengrundlage der Dashboards wird automatisch in einem festgelegten Zeitintervall geupdated. Dadurch wird sichergestellt, dass die Tabellen und Grafiken stets aktuelle Daten präsentieren.
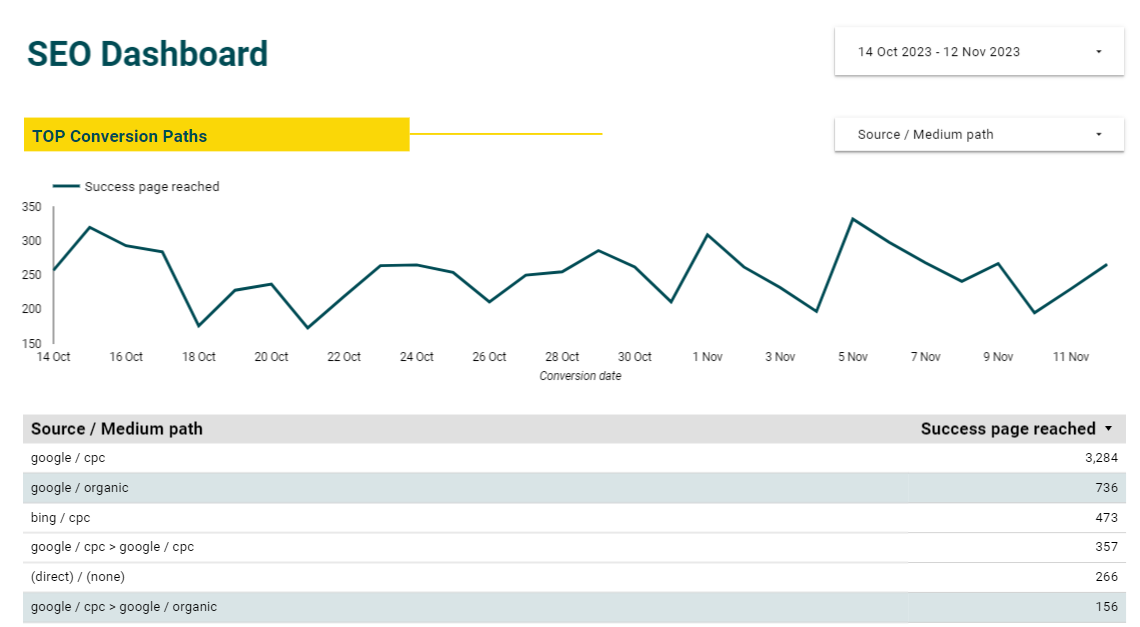
Abbidung 2: Beispielhafte Darstellung eines Dashboards auf Basis automatisch aktualisierter Daten


