

Large Language Models (LLMs) verändern die Suchlandschaft und das Nutzerverhalten spürbar. KI-Systeme wie ChatGPT und Perplexity bestimmen nicht nur wie Menschen suchen, sondern zunehmend auch welche Marken überhaupt sichtbar werden. Damit verschiebt sich Sichtbarkeit von Rankings hin zur Auswahl der genannten Marken.
Dieser Beitrag zeigt, wie Large Language Models Inhalte auswählen, wie sich Sichtbarkeit durch KI-basierte Antworten verändert und welche Rolle LLMO (Large Language Model Optimization) künftig für Marken und Unternehmen spielt.
Die zentrale Frage lautet also: Was müssen Unternehmen heute tun, um in KI-basierten Antworten sichtbar zu werden?
Large Language Models (LLMs): Was sind LLMs?
Large Language Models (kurz LLMs) sind KI-Modelle, die menschliche Sprache verstehen und erzeugen können. Sie bilden die technologische Grundlage für Systeme wie ChatGPT und Perplexity, generative Suchfunktionen oder KI-basierte Assistenten.
Während klassische Suchmaschinen vor allem Ergebnisse auflisten, versuchen LLMs dem Nutzer direkt eine möglichst passende Antwort zu liefern. Dafür analysieren sie Sprache nicht auf Keyword-Ebene, sondern auf Bedeutungs-, Kontext- und Beziehungsebene und erzeugen daraus Antworten für die Nutzer.
Warum LLMs keine klassichen Suchmaschinen sind
LLMs funktionieren nicht wie die klassischen Suchmaschinen und hier liegt auch der entscheidende Unterschied, denn:
Suchmaschinen zeigen dem Nutzer Optionen, LLMs geben direkt Entscheidungen vor.
Über die klassische Google-Suche erhält der Nutzer eine Auflistung verschiedener Websiten für die Suchanfrage und entscheidet selbst, welche Quelle er anklickt. In Chatbots oder generativen Suchfunktionen bekommt man oft eine fertige Antwort, die teilweise ergänzt wird durch Quellen (teilweise aber auch nicht).
Für Nutzer ist die Suche bequem. Für Unternehmen bedeutet das aber viel mehr: Sichtbarkeit und Markenrelevanz entsteht nicht mehr nur über Rankings, sondern ob Inhalte in den LLMs aufgenommen und ausgespielt werden.
Darum sind LLMs für Unternehmen relevant: Beispiel ChatGPT
ChatGPT zählt 2025 zu den meistgenutzten digitalen Plattformen weltweit und ist auch in Deutschland für viele Menschen ein fester Bestandteil im Alltag. Schätzungen zufolge nutzen deutschlandweit über 20 Millionen Menschen ChatGPT mindestens einmal pro Monat, rund 5-6 Millionen sogar täglich. Etwa 40 Prozent der Bevölkerungen haben den Dients bereits genutzt und insbesondere bei der jüngeren Zielgruppe ist die Nutzung weitverbreitet.
In Deutschland werden täglich über 100 Millionen Prompts aus ChatGPT-Nutzung generiert. Ein erheblicher Teil davon dreht sich nicht um Schreiben, sondern um Fragen wie: Welches Tool ist geeignet?, Welche Lösung passt zu meinem Problem? oder Welche Anbieter sind empfehlenswert?
Damit zeigt sich eine klare Verschiebung: Fragen zu Produkten, Anbietern oder Lösungen werden zunehmend direkt in LLMs gestellt. Die klassische Suche über Google und Co. bleibt wichtig, ist aber nicht mehr der alleinige Einstiegspunkt.
Ebenenmodell: So verarbeitet ein LLM einen Satz
Am folgenden Beispielsatz erklären wir die technische Funktionsweise von einem LLM. Dies ist wichtig, um darauf basierend zu verstehen, wie Marken und Unternehmen von einem LLM als Quelle angegeben werden.
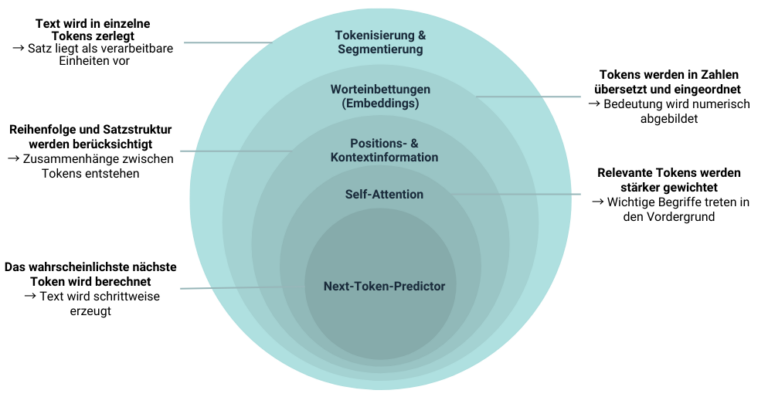
1. Tokenisierung & Segmentierung
Zuerst zerlegt das LLM den Satz in kleinere Einheiten, sogenannte Tokens. Diese bestehen aus Wörtern, Wortteilen oder Zeichenfolgen.
Vereinfacht könnte das so aussehen: [“Der”, “Hund”, “ist”, “groß”]
Das Modell verarbeitet diese Tokens einzeln, also als Abfolge einzelner Einheiten und nicht als vollständigen Satz. Jedes Token wird einzeln weiterverarbeitet. Grammatik, Satzbau oder Bedeutung entstehen erst später durch weitere Verarbeitungsschritte.
2. Vektorisierung (Embeddings)
Jedes Token wird in einen numerischen Vektor, also eine numerische Repräsentation, überführt (sogenanntes Embedding). Diese Vektoren bilden keinen festen Wortwert ab, sondern eine Bedeutungsposition im Sprachraum. Wörter mit ähnlicher Bedeutung oder Nutzung liegen im Vektorraum nahe beieinander.
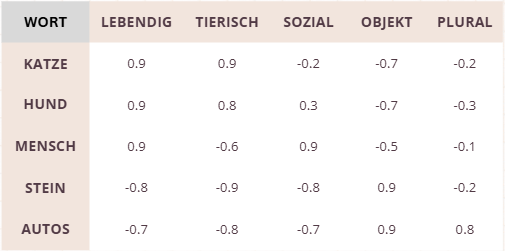
Dabei erkennt das Modell zum Beispiel:
- „Hund“ liegt nahe bei Wörtern wie Katze, Tier, Haustier
- „groß“ liegt nahe bei klein (als Gegensatz), hoch, riesig
- „ist“ liegt nahe bei anderen Hilfs- oder anderen Verben
Wichtig: Die Bedeutung eines Tokens ist nicht absolut, sondern statistisch gelernt aus Milliarden von Textbeispielen.
3. Positions- & Kontextinformation
Damit das Modell versteht, in welcher Reihenfolge Tokens auftreten, werden sogenannte Positionsinformationen ergänzt. Ohne diesen Schritt wären alle Tokens nur eine ungeordnete Menge.
Durch diese Positionskodierung kann das Modell erkennen:
- dass „Hund“ das Subjekt ist
- dass „ist“ eine Verbindung herstellt
- dass „groß“ eine Eigenschaft beschreibt
Erst hier entsteht ein erstes strukturelles Verständnis des Ausdrucks.
4. Kontextbewertung (Self-Attention)
Jetzt kommt der zentrale Mechanismus moderner LLMs: Self-Attention.
Dabei berechnet das Modell, wie stark jedes Token mit jedem anderen Token zusammenhängt. Tokens mit höherer Relevanz für die Anfrage erhalten mehr Gewicht. So entsteht eine Art Gewichtung:
Im Beispiel:
- „Hund“ ist der zentrale Begriff
- „groß“ beschreibt direkt „Hund“
- „Der“ und „ist“ sind grammatikalisch notwendig, aber inhaltlich weniger wichtig
Das Modell lernt so, welche Teile der Eingabe inhaltlich entscheidend sind und welche eher unterstützend wirken. Dieser Schritt wird über viele Schichten hinweg wiederholt und verfeinert.
5. Antwortgenerierung (Next-Token-Vorhersage)
Nachdem Bedeutung, Reihenfolge und Relevanz der Tokens bestimmt wurden, nutzt das LLM dieses Kontextwissen zur Texterzeugung. Ein LLM ist im Kern ein Next-Token-Predictor. Es versucht nicht, Inhalte nachzuschlagen, sondern berechnet: „Welches Token folgt mit der höchsten Wahrscheinlichkeit als Nächstes?“
Auf Basis des gelernten Kontexts könnte das Modell z. B. intern Wahrscheinlichkeiten aufbauen.
Das Token mit der höchsten Wahrscheinlichkeit wird ausgewählt, an den Text angehängt und der gesamte Prozess beginnt erneut.
Durch diese iterative Wahrscheinlichkeitsrechnung entstehen vollständige Sätze, strukturierte Antworten und scheinbar erklärende Texte, ohne dass das Modell „weiß“, was wahr oder falsch ist.
Wie LLMs Inhalte und Marken auswählen
Ob ein Unternehmen, eine Marke oder eine Website in KI-Antworten auftaucht, ist kein Zufall. Ein LLM “liest” nicht Websitetexte wie eine Suchmaschine, die nach passenden Keywords sucht. Stattdessen versucht das LLM zu verstehen, was gemeint ist. Damit folgen LLMs einer Kombination aus semantischer Einordnung, Vertrauensbewertung und technischer Verwertbarkeit.
1. Entitäten statt Keywords
Der wichtigste Unterschied zur klassischen SEO liegt in der Art, wie Relevanz definiert wird. LLMs arbeiten nicht keywordbasiert, sondern entitätsbasiert. Eine Entität ist für ein Modell etwas Eindeutiges: ein Unternehmen, ein Produkt, eine Organisation, eine Kategorie oder ein klar abgegrenztes Fachthema.
Konkret bedeutet das also:
Wenn ein Nutzer beispielsweise nach einer bestimmten Softwarelösung fragt, sucht ein LLM nicht nach Seiten mit möglichst vielen passenden Wortkombinationen. Stattdessen versucht es einzuordnen, welche Anbieter oder Marken in diesem Themenfeld als relevante Referenzen gelten. Entscheidend ist, ob eine Marke über mehrere Inhalte hinweg konsistent mit einem bestimmten Kontext verknüpft ist und wahrgenommen wird.
Relevanz entsteht also nicht isoliert, sondern über Wiedererkennbarkeit. Wer ein Thema regelmäßig, fokussiert und aus einer klaren fachlichen Perspektive behandelt, wird für das Modell leichter zuordbar.
2. E-E-A-T: Das Vertrauenssignal für LLMs
Relevanz allein reicht nicht. LLMs müssen einer Quelle auch vertrauen können. Genau hier kommt E-E-A-T-Prinzip ins Spiel und steht für:
- Experience (Erfahrung)
- Expertise (Fachwissen)
- Authoritativeness (Autorität)
- Trustworthiness (Verlässlichkeit)
Für ein Sprachmodell zeigt sich Vertrauen vor allem durch Transparenz: Wer ist der Autor? Welches Unternehmen steht dahinter? Wie aktuell sind die Inhalte?
Seiten, die diese Informationen klar ausweisen und ihre Inhalte regelmäßig pflegen, wirken für LLMs deutlich verlässlicher als anonyme oder veraltete Quellen.

3. Struktur und technische Verwertbarkeit
Selbst relevante und vertrauenswürdige Inhalte werden von LLMs nicht berücksichtigt, wenn sie technisch schwer verwertbar sind.
Sprachmodelle bevorzugen – ähnlich wie AI Overviews – Inhalte, die klar strukturiert und logisch segmentiert sind. Überschriften, sauber abgegrenzte Absätze, Listen oder Tabellen helfen dem Modell dabei, Informationen eindeutig zu identifizieren und korrekt einzuordnen.
4. Micro-Content statt langer Fließtexte
Aus dieser Logik ergibt sich die wachsende Bedeutung von Micro-Content. Gemeint sind kurze, präzise Inhalte, die für sich allein funktionieren: Definitionen, Schritt-für-Schritt-Erklärungen, kompakte Erläuterungen oder klar formulierte Antworten auf konkrete Fragen. Diese Formate sind für LLMs ideal, da sie schnell und einfach extrahierbar sind.
Was bedeutet LLMO in diesem Kontext?
LLMO – Large Language Model Optimization – beschreibt genau die strategische und operative Ausrichtung von Inhalten auf Sprachmodelle. Es geht nicht darum, Texte künstlich für KI umzuschreiben, sondern Inhalte so aufzubereiten, dass sie verständlich, eindeutig und technisch verwertbar sind.
Während SEO dafür sorgt, dass Inhalte gefunden und indexiert werden, entscheidet LLMO darüber, ob sie Teil einer KI-Antwort werden. LLMO ist damit keine Alternative zu SEO, sondern eine zusätzliche Einheit, die unbedingt in einer umfassenden Marketingstrategie berücksichtigt werden sollte.
Fazit
Rankings bleiben wichtig, verlieren aber ihre alleinige Bedeutung. Entscheidend ist zunehmend, ob Inhalte als relevant und vertrauenswürdig wahrgenommen werden.
LLMO beschreibt genau diesen Wandel. Wer künftig sichtbar bleiben will, muss verstehen, wie Sprachmodelle Inhalte lesen, bewerten und auswählen.
Als Performance Marketing und GEO-Agentur unterstützen wir Sie nicht nur dabei, zu verstehen, ob und wie Ihr Unternehmen in LLMs stattfindet und wie daraus messbare Sichtbarkeit entsteht, sondern begleiten Sie mit einer ganzheitlichen Beratung von der Analyse bis zur operativen Umsetzung von LLMO-Maßnahmen.